


In the 18th century, Europe and the United States (U.S.) saw the beginnings of the first industrial revolution. Textiles, steam power, and machine tools mechanized the production of items that had previously been created by the hands of human workers. The first industrial revolution extended beyond improvements in the manufacturing process to include societal impacts such as population growth and average household income.
The second industrial revolution occurred from about the late 19th century to the early 20th century and was also known as the Technological Revolution. Innovations during this period included the telephone, typewriter, lightbulb, motor cars, and powered flight. The third industrial revolution, the Digital Revolution, began around 1950 and ranged through the 1970s. This Digital Revolution advanced computing and telecommunications by transitioning from analog to digital products and services. The fourth industrial revolution, as described by Klaus Schwab [1], builds on the third industrial revolution and is characterized by the fusion of the physical, digital, and biological spheres. The fourth industrial revolution is distinguished from the third by the velocity, scope, and systems impacts of the emerging technologies. These technologies include Artificial Intelligence (AI), robotics, and quantum computing, among others [1].
As the fourth industrial revolution takes shape, many countries, businesses, and non-governmental organizations place acquiring these technologies at the forefront of their objectives. In 2018 the United States released its AI Strategy which directed the U.S. Department of Defense (DoD) to use AI to “transform all functions of the Department” [2]. The DoD was expected to scale AI’s impact across the department through a common foundation. This foundation would be comprised of shared data, reusable tools, frameworks, and standards. In parallel with this common foundation, the DoD was to digitize existing processes and to automate wherever possible [2].
Schwab [1] asserted that technologies in the fourth industrial revolution should build on the principles and technologies from the third industrial revolution. In the case of AI, enterprise-wide digitization and automation for human-centric processes must occur to enable data creation, tagging, and storage for future AI applications. Algorithmic training will be incomplete without the digitization and automation of these processes. Dr. Launchbury from the Defense Advanced Research Projects Agency (DARPA) summed up the impacts of incomplete and inaccurate data when he stated that “skewed training data creates maladaptation” [3] of resultant AI.
Despite the national guidance for digitization and automation, there is no specific implementation guidance for automation in many organizations. The DoD has begun the process of developing specific automation guidance. Many DoD efforts in this domain are currently top-down directed with a narrow focus on AI in specific projects. A bottom-up strategy will enable Program Managers (PMs), responsible for different systems, to generate procurement requirements to incrementally advance technology across the automation spectrum. An automation foundation will provide the broad network of data capabilities for successful development and deployment of future AI-enabled applications and technologies.
A bottom-up implementation strategy requires a common understanding and lexicon for developing requirements. Using definitions from academia or professional literature could prove problematic. Such definitions must be broad enough to cover all procurement aspects while still being standardized. For example, there are many published AI descriptions which are so different that they defy standardization. Published definitions range from conceptual to operational and published categorizations range from 3, 4, 5, or 7 types of AI categories depending on your source document [4, 5, 6, 7].
For the purposes of generating, codifying, and communicating system requirements a different approach is required. That approach must be broad enough to apply to a multitude of capabilities but be adequately standardized. Therefore, we propose utilizing the automation spectrum [8].
The Automation Spectrum
The Automation Spectrum includes all automation possibilities ranging from fixed automation, which is rules-based, to evolutionary automation, which is based on statistical methods for learning how to produce desirable outcomes (see Fig. 1). As the capability moves towards fully automated self-control, the complexity also increases. The range of automation capabilities could include simple automation such as a windmill or an alarm clock to more complex automation such as macros or batch programs to autonomous capabilities.
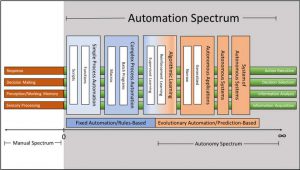
Figure 1: Automation Spectrum – (Source: Author)
Within the automation spectrum is the autonomy spectrum or the spectrum for those capabilities that are self-governing. AI falls within the autonomy spectrum and includes the many different types of AI, AI training methodologies, and applications of AI. Using the automation spectrum, AI is a part of the broader automation construct. Thus, all AI is automation but not all automation is AI. This axiom differs from some of the published categorization schemes for AI. However, the delineation in Fig. 1 will prove vital in acquisition processes and especially in cross-domain research and analyses. Therefore, the principle of automation and autonomy spectrums must be the foundation for establishing procurement and requirements guidance.
The world of automation possibilities seems endless and may prove too cumbersome to sift through to establish acquisition requirements. It may be useful to examine the approach of Parasuraman, Sheridan, & Wickens [9]. They created four functional categories of automation: Information Acquisition, Information Analysis, Decision and Action Selection, and Action Execution. It was observed that the resulting functional classes were closely linked to human information processing [9] as well as being closely linked to John Boyd’s OODA (Observe Orient Decide Act) loop [10] (See Fig. 2).
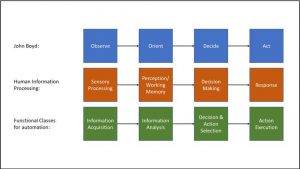
Figure 2: Mapping of Parasuraman et al.’s functional classes onto human information processing and John Boyd’s OODA Loop. – (Source: Author)
The Levels and Costs of Automation
Within a given functional class of automation, technology can take many forms with varying complexity. Technological application variance can be described and organized by defining levels of automation (LOAs). In the work previously mentioned by [9], the authors defined LOAs using a scale from 1 to 10 (see Fig. 3). Level 1 represented unassisted human operation and level 10 represented complete superseding of the human by the automated system. Like many models, abstractions in the LOA scale are unlikely to correspond exactly with one of the defined levels.

Figure 3: Levels of Automation adapted from Parasuraman et al. [9].
It is important to note that levels 2 through 10 of the LOA scale can be applied to any section of the automation spectrum. For example, at its basic definition, level 2 of the LOA scale is the “Automated Counterpart (AC) offers a complete set of decision/action alternatives.” In simple automation, the decision/action alternatives could be produced from rules-based programming such as pre-determined ‘if-then’ statements in scripts or functions. Or, using an autonomous AC, the decision/action alternatives could be produced from machine learning and AI applications.
When assessing current and desired future automation states for specific technology capabilities, the LOA scale should first be applied to each of the four functional classes of automation individually. Then each functional class, with its LOAs, should be applied to each subsection of the automation spectrum individually. From this point, PMs can assess current LOA and functional class within the automation spectrum for the selected technology. Once the automation assessment is complete, the next step is to discern the requirements for moving the technology to the next LOA. This method of analysis provides the necessary common framework for assessing the extent to which a process is automated on an incremental basis. Methodologically, this analytical model is superior to previous simple binary classifications of whether a process is automated or not.
Oftentimes during the assessment process and creation of desired future states, there are unnecessary cultural pushes to develop more sophisticated autonomous capabilities when a simpler LOA might be better suited for the task. Factors to consider when creating desired future states consist of monetary investments for technology maturity or human skill degradation, among others. Taken together, these factors comprise the overall cost of incrementally increasing the LOA for a given technology.
In order to project overall cost, it is important to realize that the distance between adjacent LOAs is not constant and the overall cost is exponential as opposed to linear, see Fig. 4. For example, the difference between levels 2 and 3 requires an algorithm to search through the problem space of possible alternatives and use a utility function to choose options that reach a particular threshold. Hence, while moving from level 2 to level 3 is not trivial, it is not a difficult task. However, if we consider moving between levels 8 and 9, more work needs to be done. Namely, an appropriate model needs to be developed for algorithmic decision making, and there needs to an appropriate verification and validation of the system at level 8 to minimize risk from removing the human’s ability to be informed of the system’s operation at level 9. The system must have demonstrated a level of accuracy and safety. But that might take years of development, assessment, and regular field usage. There are also ethical considerations associated with determining responsibility and accountability should automation errors result in loss of life, or damage to property, etc. Consequently, the prerequisites for moving from level 8 to 9 are much higher than for levels 2 to 3.
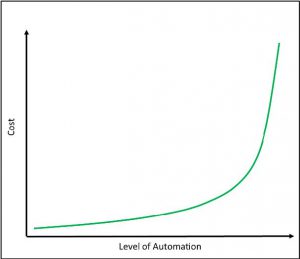
Figure 4: Representation of the relationship between increasing LOA and overall
cost. The relationship is exponential as opposed to linear. – (Source: Author)
Trust and Proper Reliance
A common misconception when discussing increasing algorithmic capabilities in the workplace is the role of trust in human-machine teams (HMT). It is often asserted that if the machine counterpart performs well, then the human user will trust it more. The fallacy here is linking machine performance directly to trust when machine performance is actually defined as the “ability” of the machine. Ability is a component of HMT trust. According to Mayer et al., characteristics of a trustee are a combination of the trustee’s ability, benevolence, and integrity [11]. Further, Hancock et al. [12] conducted a metanalysis looking at the factors that comprise HMT trust to determine which factors are the most influential in an HMT. While ability of the algorithmic counterpart was ranked highest among all the factors, there were many other factors which also affected HMT trust. Additional factors that were included in Hancock et al.’s metanalysis spanned three categories: human-related factors, automation-related factors, and environmental factors. Human-related factors covered items such as operator workload, expertise, demographics, propensity to trust, self-confidence, and task competency. Automation-related factors looked at the automation’s predictability, transparency, failure rate, false alarms, adaptability, and anthropomorphism. Finally, the environmental factors considered in the metanalysis consisted of team or tasking considerations and included items such as in-group membership, culture, communication, shared mental models, task type, task complexity, multi-tasking requirements, and the physical environment [12].
Hoff & Bashir applied the model from Mayer et al. [11] to the findings from Hancock et al.’s metanalysis [12] and devised an integrated model of trust with associated factors in HMTs [13]. Hoff & Bashir separated pre-interaction factors into three categories: dispositional trust, situational trust, and initial learned trust. These categories exist prior to any system interaction and could bias the user well before any interaction takes place. The post-interaction category is termed dynamic learned trust and is comprised of system performance and system design features. Taken together, these pre- and post-interaction categories of factors combine to form a system reliance strategy which is dynamic and changes as various components of the model change or are altered [13]. The ultimate aim of utilizing these models is to encourage appropriate user reliance on automated counterparts [14]. All of the associated factors are considerations that creators of such technologies should consider when designing for appropriate human reliance on automated technologies.
The chart in Fig. 5 depicts a simple linear reliance strategy by a human user on their algorithmic counterpart. In an effective relationship with a proper reliance strategy, actual reliability and perceived reliability increase at an equal rate. Algorithmic overtrust [16] occurs when human perception of AC reliability exceeds truth. In these cases, humans overly rely on and comply with their algorithmic counterparts. Singh et al. termed this ‘automation-induced complacency’ [17], where there is a tacit and misguided assumption that users will rely on automation more than is desired, since the system is assumed to behave optimally in most situations. In some overtrust scenarios, human users comply with ACs even when they are clearly wrong in a given task [16]. Conversely, algorithm aversion occurs when the human user believes that the AC’s actual reliability is less than reality. Algorithm aversion is especially prevalent after human users observe machine counterparts err [18]. Human users experiencing algorithm aversion may partially or entirely dismiss their machine counterpart’s contributions, advice, or inputs even if they are correct. Algorithmic overtrust and algorithm aversion can have negative consequences on factors such as performance or situational awareness. These situations can be especially hazardous within safety-critical contexts, such as medical, military or other defense scenarios.
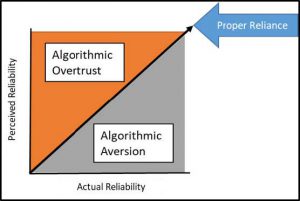
Figure 5: Graphical representation of proper reliance, adapted from Gempler [15].
The trust of human operators is an important consideration for developing automation. As the Australian Defense, Science and Technology Group put it: “future work on the human side of human–autonomous system interactions should include the development of a psychometrically reliable and valid instrument for measuring attitudes and beliefs about the general propensity to trust automated and autonomous systems.” [19] The general public and those working in policy are concerned. As the European Commission noted in their White Paper on Artificial Intelligence, trust is a prerequisite for the uptake of technology [20].
The impacts of trust and reliance are apparent in the following example. Most human decisions and actions follow a basic outline. The fundamental building blocks of this process were laid out in Fig. 2 and labelled as human information processing. In Fig. 6, the human information processing steps are visualized on a notional timeline. A false assumption regarding automation implementation is that the automation will replace the corresponding human information processing step.

Figure 6: Timeline of Human Information Processing – (Source: Author)
For example, if an automated agent were developed for information acquisition, some might assume that human sensory processing would no longer be needed. This is an incorrect assumption. Even if information acquisition is automated, the human user must ‘sense and process’ the outputs of the automated agent. However, as depicted in Fig. 7, the inclusion of automation will indeed shorten the human information processing timeline, without directly replacing any human processes.
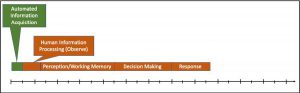
Figure 7: Human Information Processing Timeline with Automated Information Acquisition – (Source: Author)
However, human trust and reliance are susceptible to fluctuations in AC ability and other factors such as usability features of the system, system appearance, ease-of-use, communication style, transparency, or the operator’s level of control [21]. As previously discussed, human users are already potentially biased by their perceptions of the system, which are informed by pre-existing dispositional factors and contextual situational factors as defined by Hoff & Bashir [13]. The combination of these factors could result in deviations from an appropriate reliance strategy resulting in the human user drifting towards algorithmic overtrust or algorithm aversion.
Fig. 8 depicts the impacts of algorithm aversion on the notional timeline. Unless the effects of ability fluctuations and operator bias are minimized, inclusion of automation could result in worse performance than if the AC were never included.

Figure 8: Timeline of Human Information Processing with algorithm aversion. (Source: Author)
Conversely, if algorithmic overtrust occurs as depicted in Fig. 9, the human user may neglect monitoring the AC due to overestimating the AC’s ability. As a result, the system may perform unchecked erroneous actions, cause incidents, or fail without immediate notice. This chain of events leads to greater resources and time required to diagnose and understand problems which are only noticed by the human user after the fact.
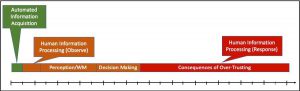
Figure 9: Timeline of Human Information Processing with algorithm overtrust. – (Source: Author)
Conclusion
This simple example highlights the complex nature of trust in HMTs. The impact of automation inclusion in human decision processes can be a powerful and positive one but must be implemented thoughtfully. Incremental progression up the LOA scale, within functional classes and across the automation spectrum, will be essential to creating the foundation called for in U.S. national guidance as it pertains to AI and, more broadly, automation.
First, organizations implementing an automation or seeking to increase automation capabilities should establish a lexicon and common understanding for all parties associated with the generation of technology requirements, program management, acquisition, science and technology, and leadership. Second, organizations should apply the principles in this article to self-assess and make incremental technology goals. Third, as automation technology is acquired and used operationally, organizations should capture lessons learned and create quantitative methods for calculating risk, ability, feedback mechanisms, and statements of confidence from automated counterparts. These refinements are necessary to develop HMT trust across the automation spectrum.
References
- Schwab, Klaus. The fourth industrial revolution. Currency, 2017.
- U.S. Department of Defense. (2018). Summary of the 2018 Department of Defense Artificial Intelligence Strategy: Harnessing AI to Advance our Security and Prosperity. Washington D.C.
- Launchbury, John. “DARPA Perspective on AI.” DARPA. https://www.darpa.mil/about-us/darpa-perspective-on-ai (accessed May 11, 2020).
- Uj, Anjali. “Understanding Three Types of Artificial Intelligence.” Analytics Insight. https://www.analyticsinsight.net/understanding-three-types-of-artificial-intelligence/ (accessed May 11, 2020).
- Hintze, Arend. “Understanding the Four Types of Artificial Intelligence.” Government Technology. https://www.govtech.com/computing/Understanding-the-Four-Types-of-Artificial-Intelligence.html (accessed May 11, 2020)
- Bekker, Alex. “5 Types of AI to Propel Your Business.” Science Soft. https://www.scnsoft.com/blog/artificial-intelligence-types (accessed May 11, 2020).
- Joshi, Naveen. “7 Types of Artificial Intelligence.” Forbes. https://www.forbes.com/sites/cognitiveworld/2019/06/19/7-types-of-artificial-intelligence/#436af704233e (accessed May 11, 2020).
- Flemisch, Frank, Anna Schieben, Johann Kelsch, and Christian Löper. “Automation spectrum, inner/outer compatibility and other potentially useful human factors concepts for assistance and automation.” Human Factors for assistance and automation (2008).
- Parasuraman, Raja, Thomas B. Sheridan, and Christopher D. Wickens. “A model for types and levels of human interaction with automation.” IEEE Transactions on systems, man, and cybernetics-Part A: Systems and Humans 30, no. 3 (2000): 286-297.
- Marra, William C., and Sonia K. McNeil. “Understanding the Loop: Regulating the Next Generation of War Machines.” Harv. JL & Pub. Pol’y 36 (2013): 1139.
- Mayer, R. C., Davis, J. H., & Schoorman, F. D. (1995). An integrative model of organizational trust. Academy of management review, 20(3), 709-734.
- Hancock, P. A., Billings, D. R., Schaefer, K. E., Chen, J. Y., De Visser, E. J., & Parasuraman, R. (2011). A meta-analysis of factors affecting trust in human-robot interaction. Human factors, 53(5), 517-527.
- Hoff, K. A., & Bashir, M. (2015). Trust in automation: Integrating empirical evidence on factors that influence trust. Human factors, 57(3), 407-434.
- Celaya, A. & Yeung, N. (2019). Human Psychology and Intelligent Machines. NDC Research Papers No. 6: The Brain and the Processor, Rome, Italy. [Online]. Available : http://www.ndc.nato.int/research/research.php?icode=0. (accessed May 11, 2020).
- Gempler, Keith Stewart. Display of predictor reliability on a cockpit display of traffic information. ILLINOIS UNIV AT URBANA, 1999.
- Robinette, P., Li, W., Allen, R., Howard, A. M., & Wagner, A. R. (2016, March). Overtrust of robots in emergency evacuation scenarios. In The Eleventh ACM/IEEE International Conference on Human Robot Interaction (pp. 101-108). IEEE Press
- Singh, I. L., Molloy, R., & Parasuraman, R. (1993). Automation-induced” complacency”: Development of the complacency-potential rating scale. The International Journal of Aviation Psychology, 3(2), 111-122.
- Dietvorst, B. J., Simmons, J. P., & Massey, C. (2015). Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology: General, 144(1), 114.
- Davis, S. E. (2019). Individual Differences in Operators’ Trust in Autonomous Systems: A Review of the Literature, Joint and Operations Analysis Division, Defence Science and Technology Group, Australian Government.
- European Commission (2020). White Paper on Artificial Intelligence: A European Approach to Excellence and trust, [Online]. Available: https://ec.europa.eu/info/sites/info/files/commission-white-paper-artificial-intelligence-feb2020_en.pdf (accessed: May 11, 2020).
- Celaya, A. & Yeung, N. (2019). Confidence and Trust in Human-Machine Teaming. HDIAC Journal, 6(3), 20-25. [Online]. Available: https://www.hdiac.org/journal-article/confidence-and-trust-in-human-machine-teaming/ (accessed: May 11, 2020).